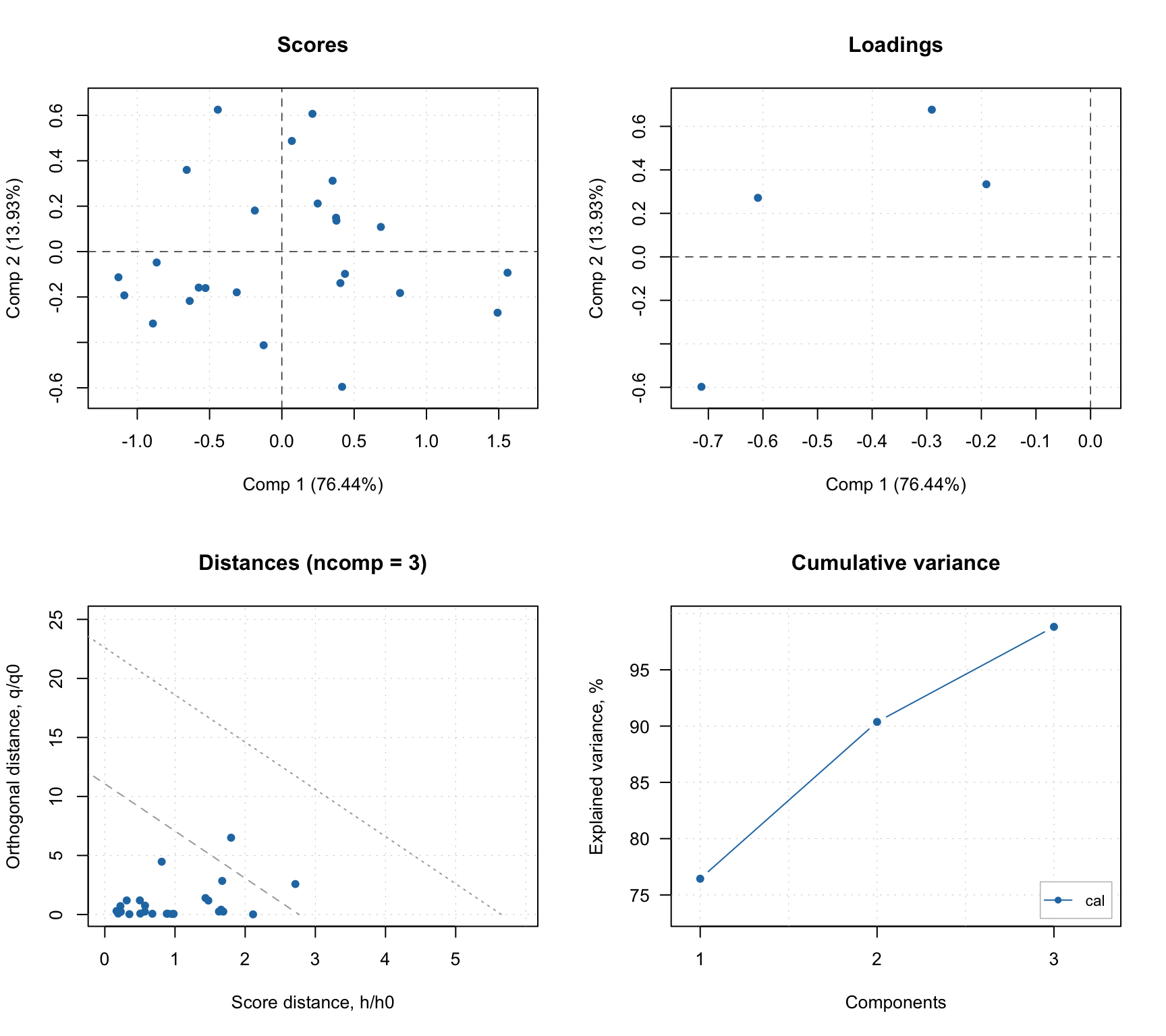
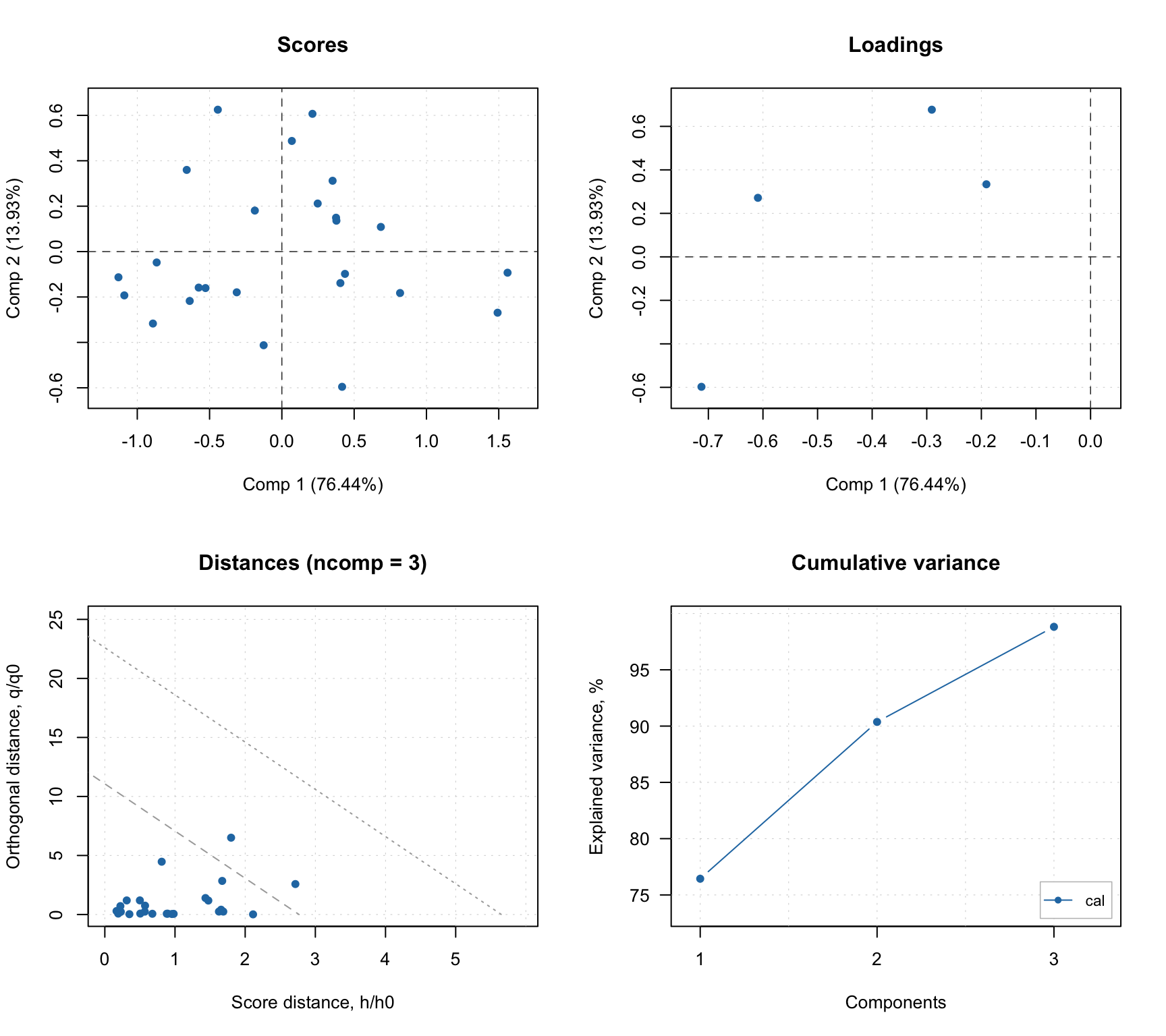
Tucker DD-SIMCA
Because the Tucker-based DD-SIMCA is very similar to the conventional and PARAFAC DD-SIMCA, we will show only what is different here and omit the rest of the functionality.
The main difference between PARAFAC and Tucker is that for Tucker, matrices A, B, and C may have different numbers of components/factors, e.g. \(N_A\), \(N_B\), \(N_C\). So when you train the model you need to provide all three numbers, not just one.
The first number, \(N_A\), is treated as the maximum number of components. ddsimca.tucker() will create \(N_A\) decompositions, starting from \([1, N_B, N_C]\) and ending with \([N_A, N_B, N_C]\). So when you select the optimal number of components, or when you show a plot with figures of merit vs. the number of components, it is always the sample-mode component that varies — the other two are fixed.
Therefore the main difference is that the value of ncomp for ddsimca.tucker is a tuple of three numbers.
Here is how to train the model:
##
## DD-SIMCA-TUCKER model for class 'target' (50 x 40)
##
## Tucker ranks: (1x2x3-3x2x3) total, (3x2x3) optimal
## Number of components: 3
## Number of selected components: 3
## Alpha: 0.05
## Gamma: 0.01
##
## Expvar Cumexpvar In Out TP FN Sens
## Cal 0.003073 99.51 79 1 79 1 0.9875As you can see, the line with the total number of components shows three items: 3 — the maximum number of components for the sample mode; 1x2x3 — the smallest number of components in the model; and 3x2x3 — the largest. As mentioned above, the last two are fixed while the first varies from 1 to the maximum number.
Here is what happens if you change the optimal number:
##
## DD-SIMCA-TUCKER model for class 'target' (50 x 40)
##
## Tucker ranks: (1x2x3-3x2x3) total, (2x2x3) optimal
## Number of components: 3
## Number of selected components: 2
## Alpha: 0.05
## Gamma: 0.01
##
## Expvar Cumexpvar In Out TP FN Sens
## Cal 2.96 99.5 79 1 79 1 0.9875The number of components is also related to the sample mode, so 1 here means \(1\times2\times3\), and so on.
Like in PARAFAC, you can show the factors as plots — just remember that the number of factors for B and C can be different (as in our model, we have 2 factors for B and 3 factors for C):
The third C factor is clearly just noise, though.
All other functionality is identical to PARAFAC DD-SIMCA.
If you want to find optimal efficiency across all 3 modes, just use loops. Here is an example where we will search for the best combination of \(N_A\), \(N_B\), \(N_C\) in a range \([1, 3]\):
library(pheatmap)
eff <- matrix(0, 9, 3)
labels <- rep("", 9)
n <- 1
for (b in 1:3) {
for (c in 1:3) {
a <- min(c(3, b * c))
m <- ddsimca.tucker(X3w, "target", ncomp = c(a, b, c))
r <- predict(m, X3wb, c.test)
eff[n, 1:a] <- r$simca$outcomes$moments$eff
labels[n] <- sprintf("%dx%d", b, c)
n <- n + 1
}
}
colnames(eff) <- 1:3
rownames(eff) <- labels
pheatmap(t(eff),
main = "Efficiency",
cluster_rows = FALSE,
cluster_cols = FALSE
)